Accelerating linear algebra with graph neural networks
Pioneering the use of graph neural networks as a computational primitive for accelerating numerical algorithms.
Linear algebra is a cornerstone of scientific computing, as well as one of the computational bottlenecks when solving optimization problems or partial differential equations. While reliable general-purpose methods exist, many applications can benefit tremendously from tailored methods that fully exploit the structure of a given problem. This, however, requires expert knowledge, yet even that may not achieve maximum efficiency.
We are pioneering a research direction that uses graph neural networks (GNNs) to learn components of classical numerical algorithms, thereby accelerating them without sacrificing reliability. The key insight is that sparse matrices have a natural graph structure: the sparsity pattern defines edges, and matrix entries define features. GNNs are therefore a natural computational primitive for learning over matrices.
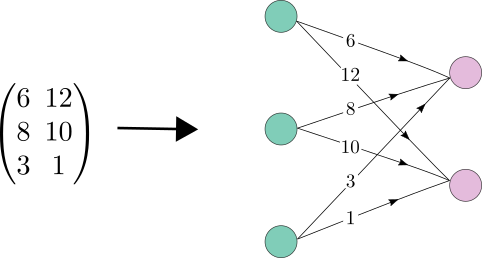
A matrix has a natural graph representation: rows and columns become nodes, and nonzero entries become edges.
Neural incomplete factorization
Our first major result was NeuralIF, a GNN that learns incomplete factorization preconditioners for the conjugate gradient method. At the core is a novel message-passing block, inspired by sparse matrix theory, that aligns with the objective to find a sparse factorization of the matrix. NeuralIF significantly speeds up convergence and reduces total solving time compared to classical preconditioners without fill-ins. In a follow-up, we extended this approach to learn incomplete factorizations for the more general GMRES solver, handling non-symmetric systems.
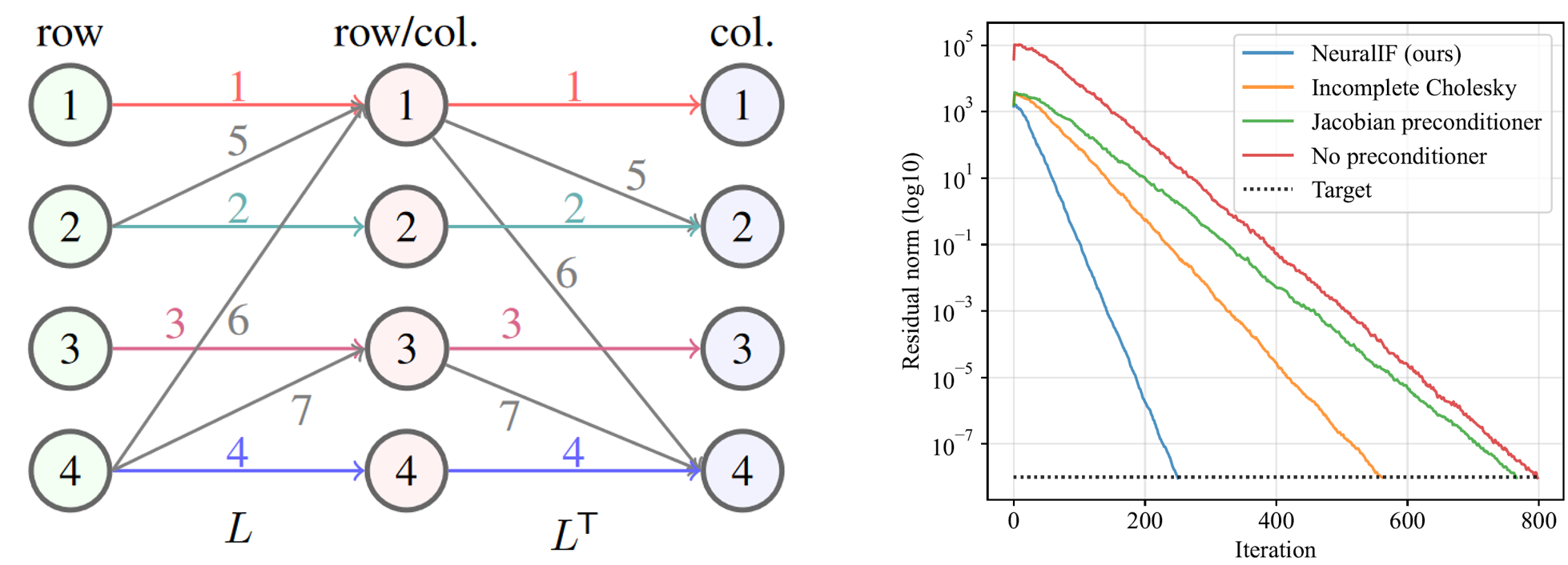
NeuralIF learns a sparse factorization via message passing on the matrix graph (left), dramatically accelerating convergence of the conjugate gradient method (right).
- Häusner P, Öktem O, and Sjölund J. Neural incomplete factorization: learning preconditioners for the conjugate gradient method. Transactions on Machine Learning Research (2024).
- Häusner P, Nieto Juscafresa A, and Sjölund J. Learning incomplete factorization preconditioners for GMRES. Northern Lights Deep Learning Conference (2025).
Accelerating optimization solvers
Beyond preconditioning, we are exploring how GNNs can accelerate optimization solvers directly. For quadratic programs (QPs) with linear constraints, we use a GNN to predict a warm-start for an active-set solver, reducing the number of iterations needed to reach the optimal solution. The QP and its constraints are represented as a graph, and the GNN performs node-level prediction to identify the likely active set.

A GNN maps the QP graph representation to an active-set prediction, warm-starting the solver.
We have also shown that distributed ADMM iterations have a one-to-one correspondence with GNN message passing. Exploiting this connection, we train a GNN to predict adaptive step sizes and communication weights for ADMM, improving convergence speed and solution quality compared to standard ADMM—without sacrificing convergence guarantees.
- Schmidtobreick E J, Arnström D, Häusner P, and Sjölund J. Warm-starting active-set solvers using graph neural networks. Learning for Dynamics & Control (L4DC), 2026.
- Doerks H, Häusner P, Hernández Escobar D, and Sjölund J. Learning to accelerate distributed ADMM using graph neural networks. Learning for Dynamics & Control (L4DC), 2026.
Earlier work
Our first work in this direction considered nonnegative matrix factorization, where we adopted the König graph representation and framed constrained low-rank factorization as a graph problem solved by interleaving a GNN with ADMM.
- Sjölund J and Bånkestad M. Graph-based neural acceleration for nonnegative matrix factorization. arXiv (2022).